
OOP 개념과 이해
들어가기전
본 포스팅은 객체 지향 프로그래밍(OOP, Object-Oriented Programming)의 개념에 대해 상세히 다룰 예정이다. 객체 지향의 개념과 추상화에 대한 개념 부분은 이전 포스팅 “객체지향에 대해”를 참고하기 바란다.
학습 목표
- OOP의 개념
- OOP의 등장배경
- OOP의 이점
객체 지향 프로그래밍(OOP, Object-Oriented Programming)

OOP는 컴퓨터 프로그래밍의 하나의 패러다임으로써, 실제 세계에 기반을 둔 모델을 모듈화하기 위해 추상화를 사용하는 프로그래밍 패러다임이다.
이 패러다임은 논리적인 수행을 중심으로 개발하였던 전통적인 소프트웨어의 개발 방식을 완전히 새로운 시각으로 바라본 혁명적인 개념으로써 동작보다는 객체, 논리보다는 자료를 바탕으로 구성한다.
이러한 개발 방식의 변화는 무엇보다 전통적인 소프트웨어의 개발 방식의 한계를 보완하고자 등장했다.
OOP의 등장
기존의 전통적인 개발 방법론은 논리적인 프로세스에 따라서 입력을 받아 처리한 다음, 결과를 내는 것이라는 생각이 지배적이었다. 따라서 프로그램을 프로그래밍한다는 것은 “어떻게 데이터를 정의할까” 보다는 “어떻게 논리를 써나가는 것인가”로 간주하였다.
Step1 → Step2 … → 결과
이처럼 동작 순서 또는 논리를 우선순위를 두어 프로그래밍하는 개발 방법론을 절차지향 프로그래밍이라 하고 OOP가 등장하기 전에 전통적인 소프트웨어의 개발 방법론은 절차지향 프로그래밍을 따랐다.
일반적으로 이 절차지향 프로그래밍의 개발 방식은 필요한 기능들을 함수로 만들고 그 함수에 필요한 입력은 반드시 전역이나 전달 인자로 정의했다. 이는 수직적인 구조를 갖게 되는 동시에 데이터는 자연스럽게 위에서 아래로 전달하는 수직적인 제어 흐름으로 설계됐다.
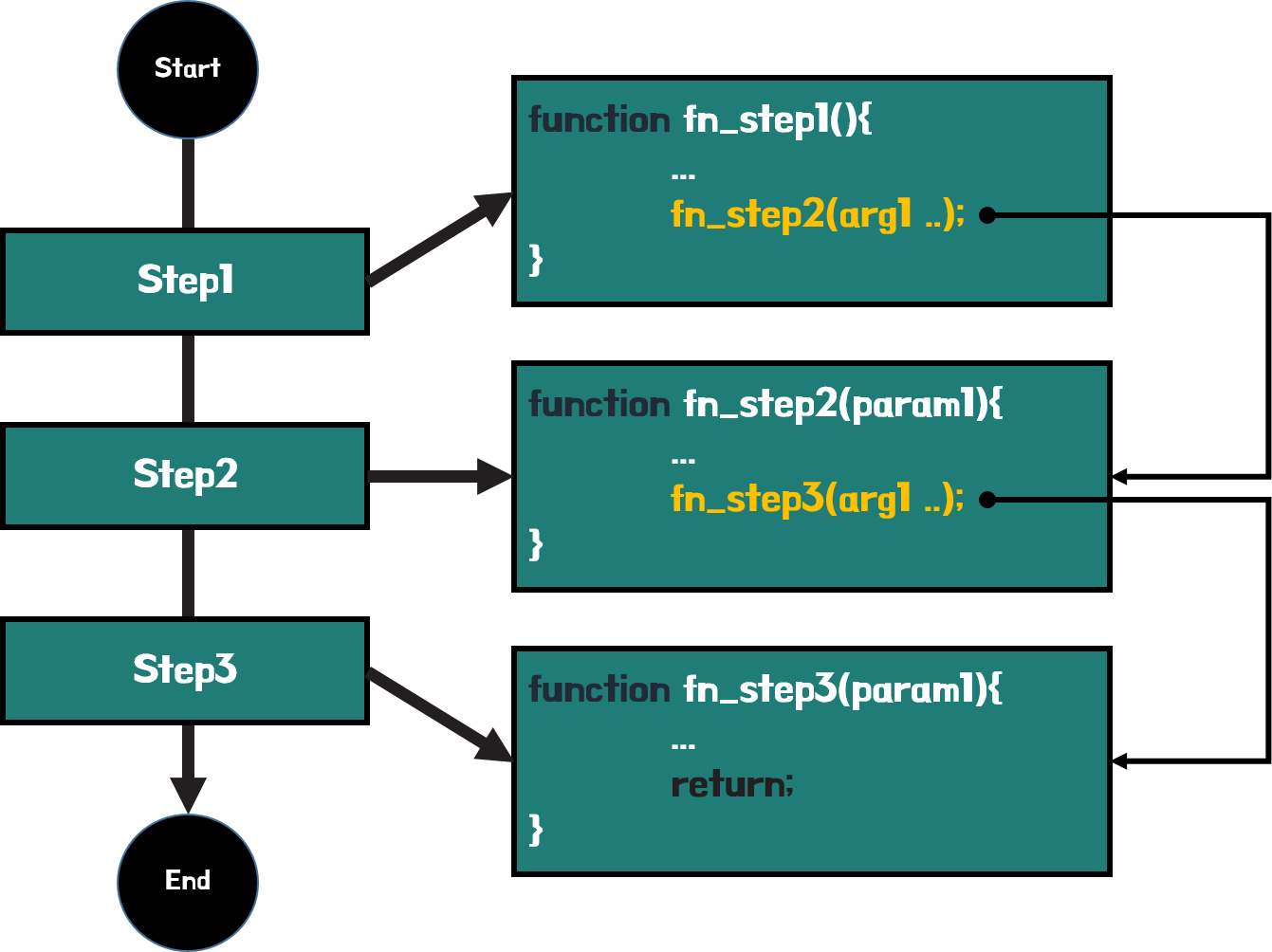
또한, 하나의 기능에 하나의 프로세스라는 특징을 지니고 있어서 데이터 흐름이 명확했고 동시에 데이터의 처리속도가 빨랐다.
- 빠른 개발 속도
- 빠른 처리 속도
- 명확한 프로세스
하지만 “하나의 기능에 하나의 프로세스”라는 고질적인 특성은 대규모 프로젝트에선 오히려 독이었다.
기능 수정과 사용자의 잦은 요구 사항은 기능의 재설계로 직결되었고 이를 해결하기 위해선 기능의 전체적인 설계를 파악해야만 했다. 결과적으로 프로젝트 버퍼(Project buffer)가 대부분 개발 기간으로 소진되고, 종종 기능 일부분을 수정하기 위해선 전체적인 설계를 수정해야 하는 경우가 발생했다.
관점의 변화 : 논리 → 객체
이러한 절차지향 개발 방식의 회고들은 개발자들에게 고찰하는 계기가 되었다. 이를 통해 소프트웨어에서 논리보다는 오히려 다루고자 하는 객체가 중요하다는 결론을 다다르게 되었고 이를 바탕으로 절차적 프로그래밍에 객체라는 개념을 포함한 OOP라는 새로운 프로그래밍의 패러다임이 등장했다.
절차지향 프로그래밍 → 객체 지향 프로그래밍(OOP)
이처럼 절차적 프로그래밍과 OOP에 대한 관점이 다른 것처럼 개발하는 방식 또한 다르다. 이점은 논리적 데이터를 실제 프로그램에서 다뤄질 물리적인 데이터로 정의할 때 명백히 차이가 드러난다. OOP는 물리적인 데이터를 자료의 추상화를 통해 객체로 구성하고 이 객체를 사용하는 개발하는 방식을 취한다.
따라서 OOP를 실현하기 위해 가장 먼저 해야 할 단계는 자료 추상화이다.
OOP의 첫 단계 : 자료 추상화
1. 추상화 → 2. 일반화 → 3. 모듈화
자료의 추상화(Data Abstraction)란 하나의 논리(기능)를 독립적인 모듈로 보기 위해 구체적인 자료형 혹은 구조를 만드는 일련의 과정을 뜻한다. 이 과정의 단계는 추상화, 일반화, 모듈화의 단계로 크게 세 가지로 분류할 수 있다.
1. 추상화 : 논리적 데이터 → 물리적 데이터
이 과정은 첫 단계는 프로그램에서 다뤄질 물리적인 데이터를 만들기 위해 논리적인 데이터들의 상호 간의 어떠한 연관성이 있는지 식별하고 관계를 맺는 작업을 한다. 이러한 작업을 추상화라 하고 흔히 데이터 모델링이라는 작업이 이와 같다.
2. 일반화 : 변수와 메소드 정의
일단 모든 논리적인 데이터를 물리적인 데이터로 추상화했다면, 이 물리적 데이터는 객체 클래스로 일반화하고 이 클래스가 담고 있는 속성과 행위를 데이터의 종류와 그것을 다룰 수 있는 모든 논리 순서로 정의한다. 정의한 데이터 종류와 논리순서는 변수와 메소드라 부른다.
3. 모듈화 : 하나의 클래스로 정의
이 일반화된 클래스는 프로그램에서 하나의 모듈로 정의되고, 또 다른 클래스에서 이 모듈을 사용하기 위해 정의한 구체적인 객체를 인스턴스라 하고, 이 인스턴스 하나를 상황에 따라 “객체” 또는 “클래스 활성체”라 한다. 즉 객체 또는 활성체는 실제 프로그램에서 다뤄질 데이터로써 정의하고 이 객체에 내포된 메소드는 수행할 명령어를 규정하고, 변수는 객체와 관련한 데이터로 규정한다.
이러한 관점의 차이로 비롯된 개발 방식의 차이는 자연스레 데이터의 제어 흐름의 차이를 만든다. 이 제어 흐름의 차이는 데이터의 소유(Own)와 조작(Manipulation)에 대한 개념을 통해 알 수 있다.
프로그래밍의 데이터의 제어 흐름의 차이
절차적 프로그래밍과 OOP의 데이터 제어 흐름 차이에서 비롯된 데이터의 소유와 조작에 대한 이해를 돕기 위해 앞서 설명한 자판기의 프로세스를 가지고 비교를 해보려 한다.
- 금액과 음료수를 입력한다.
- 음료수의 금액을 확인한다.
- 음료수 재고 돈을 계산한다.
- 자판기는 음료수와 잔돈을 반환한다.
절차적 제어 흐름 : 수직적인 제어 흐름
먼저 절차적 프로그래밍의 코드는 다음과 같다.
// TODO step1 금액과 음료수를 입력한다.
function inputInfo(userAmt, drink) {
...
choiceDrink(userAmt, drink);
}
// TODO step2 음료수의 금액을 확인한다.
function choiceDrink(userAmt, drink) {
...
calculate(userAmt, drink, drinkAmt);
}
// TODO step3 음료수 재고와 돈을 계산한다.
function calculate(userAmt, drink, drinkAmt){
...
resultAction(drink, userAmt);
}
// TODO step4 자판기는 음료수와 잔돈을 반환한다.
function resultAction(userAmt, drink) {
...
}
보다시피 하나의 동작을 하나의 함수로 정의했고, 코드는 논리적인 순서가 중점으로 작성되었다.
이러한 프로그래밍의 데이터는 함수라는 단위로 식별하여 각 기능을 제어한다. 이 말인즉슨 함수 하나의 함수마다 데이터의 소유와 조작이 각 함수의 안의 범위에서 제한적이라는 의미로써 데이터의 소유권을 다음 함수에 전달하기 위해선 전역 변수 또는 전달 인자로 전달해야만 했다.
- 함수 → 함수
- 데이터의 조작 범위 : 개발자에게 데이터 제어권을 부여
- 데이터의 소유 범위 : 매개 변수를 통해 정의
즉 함수에 필요한 데이터는 전역변수 또는 매개 변수를 통해 데이터의 소유 범위를 정하고 이러한 제어 흐름은 함수 간 강한 의존성을 띄고, 이로 인해 기능의 순서가 바뀌는 경우엔 결괏값을 보장할 수 없게 된다.
특히 결괏값을 추출하기 위한 과정에서, 데이터 조작은 프로그래밍에 있어 개발자에게 데이터 제어권을 부여한다. 데이터 조작은 일반적으로 분기문 또는 반목문을 통해 이뤄지는데 이러한 제어가 많아질수록 개발자에게 부담된다.
// TODO step2 음료수의 금액을 확인한다.
function choiceDrink(userAmt, drink) {
...
var drinkAmt = 0;
switch (drink) {
case "콜라":
drinkAmt = 1500;
break;
case "사이다":
drinkAmt = 1000;
break;
}
calculate(userAmt, drink, drinkAmt);
}
다음의 choiceDrink() 함수 코드를 보면 switch 분기문을 통해 drinkAmt의 데이터가 조작된다는 걸 알 수 있다. 다음 코드는 별문제가 없어 보이지만 “환타”라는 음료수가 추가하자는 요구사항이 왔다면 전체 코드에서 해당 음료수를 조작하는 함수를 찾아 환타라는 조건을 추가하고, 이전 함수와 이후 함수에 데이터에 영향을 미치진 않는지 검증을 해야 한다.
검증하는 도중에 오류가 발견되었다면, 이를 해결하기 위해 코드들을 수정하는 과정에서 미처 정리하지 못한 불필요한 코드(Dead code)가 남게 되고 심한 경우엔 코드가 꼬여지게 된다. 이러한 코드를 스파게티 코드라고 하는데 이 스파게티 코드들은 유지보수를 어렵게 만드는 원인이 된다.
- 기능과 기능의 강한 결합
- 개발자에 의한 데이터 조작
- 유지보수의 어려움
OOP의 제어 흐름 : 수평적인 제어 흐름
하지만 OOP는 객체와 추상화라는 개념을 통해 앞서 본 절차적 설계의 문제점들을 배제할 수 있다.
독립적인 모듈을 활용
public class Example {
public void execute() {
// 음료수 클래스
Drink cola = new Cola();
// 자판기 클래스
VendingMachine machine = new VendingMachine(2000, cola); // TODO step1 금액과 음료수를 입력한다.
machine.calculate(); // TODO step3 음료수 재고와 돈을 계산한다.
machine.resultAction(); // TODO step4 자판기는 음료수와 잔돈을 반환한다.
}
}
먼저 다음 코드를 절차적 코드와 비교해보면 순서보다는 객체라는 시각으로 프로그램을 작성했다는 점을 알 수 있다. 즉 자판기, 음료수를 독립적인 모듈로 바라보고 이를 토대로 클래스로 정의했다.
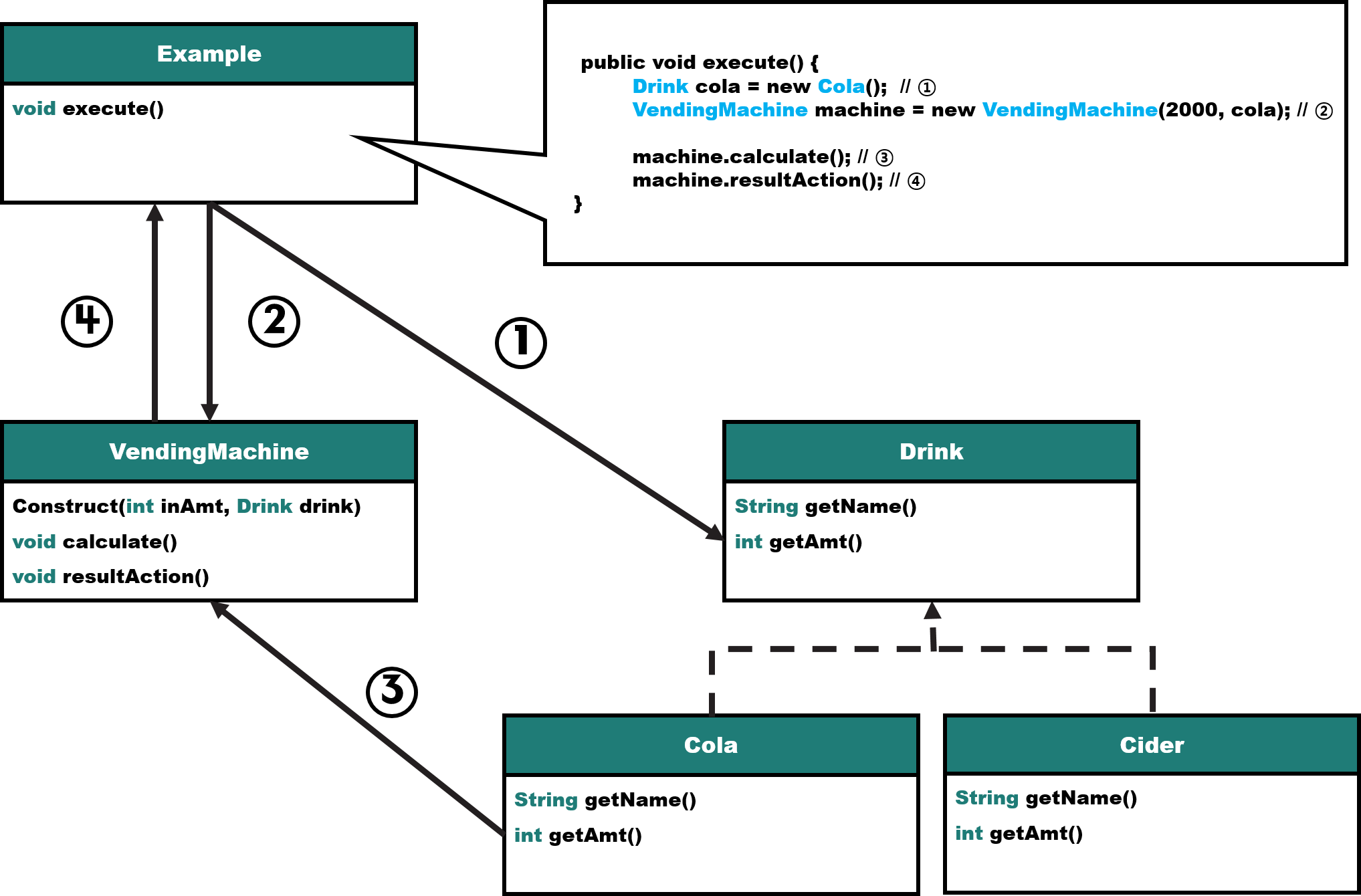
다음 클래스 유스케이스를 보면, 프로그램은 자판기 프로세스를 수행하기 위해 각 단계에서 필요한 기능을 정의된 클래스를 참조하여 해당 기능을 수행하고 있다. 이처럼 프로그램의 논리적인 순서를 지키는 과정은 절차적 프로그래밍과 유사하지만, 엄밀히 보자면 다르다.
이러한 차이는 자료의 추상화에 있는데, 공통적인 데이터와 동작을 하나의 클래스라는 틀에 정의했기 때문이다. 데이터와 동작을 하나의 틀에 정의함으로써 데이터의 소유권은 각 객체에 의해서 정해지고, 결과적으로 객체지향 설계는 객체라는 하나의 독립적인 모듈을 활용함으로써 기능 간 의존도를 최소화하기 때문에 각 기능을 독립적으로 관리할 수 있게 된다.
추상화를 통한 제어의 역전(IoC)
특히, OOP는 추상화 설계를 통해 전통적인 제어의 흐름을 바꾼다는 점이다. 예를 들어 데이터 조작이라는 관점에서 보자면 기존의 전통적인 데이터 조작은 분기문을 통해 조작에 필요한 데이터를 코드에 작성했다. 이는 실제 실행될 코드가 미리 정해져 있다는 의미다.
switch (drink) {
case "콜라":
drinkAmt = 1500;
break;
case "사이다":
drinkAmt = 1000;
break;
}
이 말을 달리 말하자면 모든 데이터의 제어권은 개발자에게 있고, 이게 바로 전통적인 제어 흐름이었다. 하지만 OOP는 클래스 추상화 설계를 통해 기존의 데이터의 제어권을 개발자가 아닌 프로그램에게 위임해줌으로써 전통적인 제어 흐름을 뒤바꾼다.
데이터의 조작 : 개발자 → 다른 대상
정리하자면 기능에 필요한 실제 코드는 개발자가 아닌 다른 대상에 의해 실행될 실제 코드가 결정되는데 이를 제어의 역전(IoC, Inversion of Control)라 불린다. 결과적으로 제어의 역전을 통해 개발자는 데이터 조작에 관해 결정하지 않아도 된다는 점이다.
이러한 예는 위에 정의한 예제 코드를 보면 알 수 있다. 눈치챘을지 모르겠지만, 위의 예제 코드엔 step2의 단계가 없다. 이 말은 음료수의 금액을 코드에 정의할 필요가 없고 개발자가 가지고 있던 데이터 제어에 대한 부담을 줄여준다는 의미이다.
본론으로 돌아와서 우리는 step2 단계가 없어진 원인을 찾기 위해선 음료수의 금액이 어디서 정의되는지 알아봐야 한다.
public void execute() {
Drink cola = new Cola();
...
machine.calculate(); // TODO step3 음료수 재고와 돈을 계산한다.
...
}
interface Drink {
public String getName();
public int getAmt();
}
class Cola implements Drink {
@Override
public String getName() {
return "콜라";
}
@Override
public int getAmt() {
return 1500;
}
}
먼저 코드를 보면 음료수라는 객체를 추상화 설계를 통해 Drink라는 인터페이스로 정의하고, 이를 구현한 Cola와 Cidar 클래스를 만들었다. 이러한 객체의 추상화 설계는 제어의 역전의 발판이 되는데 다음 calculate 메소드를 보면 그 답을 찾을 수 있다.
void calculate() {
int drinkAmt = drink.getAmt(); // TODO step2 음료수의 금액을 확인한다.
...
}
Drink drink라는 추상화 클래스를 VendingMachine 클래스의 Drink 객체를 참조한다. step1에서 VendingMachine 클래스의 Drink 객체는 Cola를 주입 받았기 때문에 Drink는 Cola를 대상으로 하고 있다.
이 때문에 drink.getAmt();를 호출하는 순간 데이터가 조작이 되고 Cola 클래스에 정의된 음료수 값을 바라보게 된다. 여기서 중요한 점은 코드상에 분기문 없이 프로그램에 의해 필요한 객체가 정의되어 데이터 조작이 가능하다는 점이다.
// 절차적 프로그래밍
switch (drink) {
...
case "환타":
drinkAmt = 900;
break;
...
}
// 객체지향 프로그래밍
class Fanta implements Drink {
...
}
가정하여 환타라는 음료수가 추가된다면, 위 코드와 같이 절차적 프로그래밍은 기존 로직에 코드를 추가해야 하지만, OOP는 기존 로직은 수정 없이 Fanta라는 객체를 만들기만 하면 된다.
OOP의 이점
결과적으로 OOP는 객체와 추상화의 개념을 통해 데이터 제어(소유, 생성, 조작)에 대한 책임을 다른 대상에게 넘겨 각 모듈/클래스 별로 정의된 기능을 유연하고 유지 보수성이 높은 프로그래밍을 할 수 있도록 지원한다.
- 기능의 독립적인 모듈화
- 기능의 유연한 확장 및 수정
- 체계적이고 효율적인 코드 관리를 통한 높은 유지 보수
- 기능의 재사용
여기서 중요한 점은 이러한 이점들은 추상화라는 개념을 발판으로 OOP의 이점들을 누릴 수 있게 된다는 점을 유의해야 한다.
마무리
OOP의 개념을 정리하기 전에 새로운 기술이 나오는 이유와 학습 방법에 대한 주관적인 생각을 말해보려 한다.
개발자들은 태생적으로 게으른 존재고 현재 기술이 비효율적이라고 생각이 들면 자연스레 효과적인 해결 방안을 제시하고 이를 바탕으로 새로운 기술이 나타난다. 이를 근거로 기술에 대한 학습 방법은 학습할 기술과 이전 기술에 대한 차이를 알아야 하고 그다음 학습할 기술을 자세히 공부해야 한다.
이 때문에 OOP와 기존의 전통적인 소프트웨어의 개발 방식에서 그 답을 찾아보려 했고, 결과적으로 OOP와 절차적 프로그래밍의 개발 방식의 차이와 데이터 제어 흐름의 차이로부터 오는 이점들을 알아볼 수 있었다. 무엇보다 OOP의 특징 중 하나인 추상화로 OOP의 제어 흐름을 설명했는데 다음 포스팅에선 이와 관련된 OOP의 특징에 대해 상세히 작성하려 한다.
참고
Introduction to Object Oriented Programming
Anti if oop
프로젝트 관리
OOP 객체지향 프로그래밍